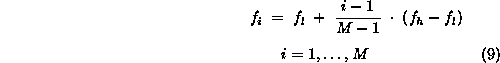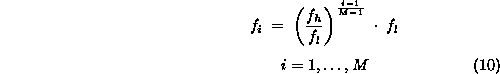Before experimenting with human perception, it is worthwhile to objectively evaluate the performance of the image-to-sound conversion system itself. In order to verify the correct functionality of the system, and to prove that the sound patterns still contain the expected image resolution, an inverse mapping was applied. The filtered analog signal, arising from the 31.25 kHz 16-b DA-conversion, was itself sampled, digitized and stored for off-line computer processing. The sound sampling was done with 8 b resolution at a 20 kHz sampling rate. Subsequently, Fourier transforms were applied using moving (overlapping) rectangular time windows of width T/64 s. No image enhancement techniques were applied to improve the perceived quality of the spectrograms. The spectrograms were directly obtained from the foregoing calculations by representing time by horizontal position, frequency (of the Fourier component) by vertical position, and amplitude (for the Fourier component) by grey-tone. Figs. 4-11 show CRT screen photographs using a 192 × 192 pixel matrix (i.e., 192 Fourier components, 192 time window positions).
| Fig. 4. Spectrogram of a sampled sound pattern for a human face, using a linear frequency distribution and a 1.05 s image-to-sound conversion time. | Fig. 6. Scene of Fig. 4, but using a doubled, 2.10 s, conversion time with the linear frequency distribution. |
![[Spectrograms of human face.]](dia17.gif)
| |
| Fig. 8. Scene of Fig. 4, but using an exponential frequency distribution with the 1.05 s conversion time. The vertical axis is logarithmically compressed. | Fig. 10. Scene of Fig. 4, but using an exponential frequency distribution and a doubled, 2.10 s, conversion time. The vertical axis is logarithmically compressed. |
| Fig. 5. Spectrogram of a sampled sound pattern for a parked car, using a linear frequency distribution and a 1.05 s image-to-sound conversion time. | Fig. 7. Scene of Fig. 5, but using a doubled, 2.10 s, conversion time with the linear frequency distribution. |
![[Spectrograms of parked car.]](dia18.gif)
| |
| Fig. 9. Scene of Fig. 5, but using an exponential frequency distribution with the 1.05 s conversion time. The vertical axis is logarithmically compressed. | Fig. 11. Scene of Fig. 5, but using an exponential frequency distribution and a doubled, 2.10 s, conversion time. The vertical axis is logarithmically compressed. |
The positions of frequencies
corresponding to the ![]() set, as programmed into
the EPROM's, are indicated by small dots along the left sides of images.
The image separating click is visible as a somewhat blurry
vertical line on the
(lower) left side of each image, within the artificial bounding frame.
In spite of the lower-quality resampling, the photographs
confirm the basic expectations. The restoration of images
proves that their content was indeed preserved in the
image-to-sound conversion.
set, as programmed into
the EPROM's, are indicated by small dots along the left sides of images.
The image separating click is visible as a somewhat blurry
vertical line on the
(lower) left side of each image, within the artificial bounding frame.
In spite of the lower-quality resampling, the photographs
confirm the basic expectations. The restoration of images
proves that their content was indeed preserved in the
image-to-sound conversion.
The resolution estimates discussed before were based on the assumption of an equidistant frequency distribution, as given by
where ![]() and
and ![]() are the lowest and highest frequency,
respectively. In the experiments described here, the
parameters are
are the lowest and highest frequency,
respectively. In the experiments described here, the
parameters are ![]() = 500 Hz,
= 500 Hz, ![]() = 5 kHz,
and M = N = 64. Figs. 4 and 5 show that with the 64 × 64 matrix, neighbouring frequencies
are barely separable for a T = 1.05 second image-to-sound
conversion time, which is as intended and expected,
because the design was meant to push towards the theoretical
limits. Using a T = 2.10 second conversion time, subsequent
frequencies are clearly separable, as shown by Figs. 6 and 7.
= 5 kHz,
and M = N = 64. Figs. 4 and 5 show that with the 64 × 64 matrix, neighbouring frequencies
are barely separable for a T = 1.05 second image-to-sound
conversion time, which is as intended and expected,
because the design was meant to push towards the theoretical
limits. Using a T = 2.10 second conversion time, subsequent
frequencies are clearly separable, as shown by Figs. 6 and 7.
Although the resolution estimates were partly based on the assumption of an equidistant frequency distribution, experiments were also done using an exponential distribution, given by
With the exponential distribution, subsequent frequencies
differ by a constant factor instead of a constant term.
An equidistant distribution does not match the properties
of the human hearing system very well, because the ear is
more sensitive to changes in the frequency of a single sinusoidal
tone at lower frequencies. The same applies to the discrimination
of multiple simultaneously sounding sinusoidal tones.
In fact, an exponential frequency distribution maps to
an approximately linear spatial distribution of excitation
along the basilar membrane in the human cochlea [2].
Subjectively, an exponential distribution is
perceived as approximately equidistant, and it is the basis
of the tempered musical scale, which has become a de facto standard
scale in music.
Another reason for abandoning the equidistant frequency distribution
was the observation of a rather dominating and hence annoying
![]() Hz tone,
as might be expected from the cross-talk components of the
image-to-sound conversion and the nonlinearities of the human
hearing system (known to give rise to combination tones).
Experiments with linearly increasing frequency differences gave
little improvement in this respect. However, no annoying
spurious sounds were heard using the exponential frequency mapping.
Because the frequency differences at the lower end of the spectrum
are now smaller than with the equidistant scheme, a resolution
less than required for preserving a 64 × 64 pixel image
with T = 1.05 s should be expected at
the bottom part of reconstructed images. This is indeed observed
from the Moiré-like distortion patterns in the bottom parts of
Figs. 8 and 9.
These patterns are due to the cross-talk among neighbouring
frequencies. The vertical (frequency) axis was logarithmically
compressed in these spectrograms to compensate for the exponential
frequency distribution. As expected, the loss of resolution at
the lower end of the spectrum, corresponding to the lower
part of the spectrograms, is most noticeable for T = 1.05 s, and
much less for T = 2.10 s, as is observed by comparing Figs.
8 and 9 with Figs. 10 and 11, respectively.
In spite of the partial loss of resolution with
the exponential distribution, the gain in perceived equidistance and
loss of spurious mixing sounds may appear to be more important in
practice. Moreover, the situation is in this respect somewhat
comparable to normal vision, in which the human retina has a region
of high resolution (the central fovea), while other regions
provide much less resolution. As with the eye, one can adapt the
camera orientation for a higher resolution at items of interest.
In all cases shown, the image-to-sound conversion is obviously of
sufficient quality to give a useful account of the visual environment.
Hz tone,
as might be expected from the cross-talk components of the
image-to-sound conversion and the nonlinearities of the human
hearing system (known to give rise to combination tones).
Experiments with linearly increasing frequency differences gave
little improvement in this respect. However, no annoying
spurious sounds were heard using the exponential frequency mapping.
Because the frequency differences at the lower end of the spectrum
are now smaller than with the equidistant scheme, a resolution
less than required for preserving a 64 × 64 pixel image
with T = 1.05 s should be expected at
the bottom part of reconstructed images. This is indeed observed
from the Moiré-like distortion patterns in the bottom parts of
Figs. 8 and 9.
These patterns are due to the cross-talk among neighbouring
frequencies. The vertical (frequency) axis was logarithmically
compressed in these spectrograms to compensate for the exponential
frequency distribution. As expected, the loss of resolution at
the lower end of the spectrum, corresponding to the lower
part of the spectrograms, is most noticeable for T = 1.05 s, and
much less for T = 2.10 s, as is observed by comparing Figs.
8 and 9 with Figs. 10 and 11, respectively.
In spite of the partial loss of resolution with
the exponential distribution, the gain in perceived equidistance and
loss of spurious mixing sounds may appear to be more important in
practice. Moreover, the situation is in this respect somewhat
comparable to normal vision, in which the human retina has a region
of high resolution (the central fovea), while other regions
provide much less resolution. As with the eye, one can adapt the
camera orientation for a higher resolution at items of interest.
In all cases shown, the image-to-sound conversion is obviously of
sufficient quality to give a useful account of the visual environment.