Closed captioning for the blind is a technique for annotating video, television broadcasts and movies such that blind people get a description of what is going on visually in a scene. Normally this is done by sending additional hidden information along, which is then decoded into for instance a spoken description. Not only does this technique require special hardware and (modified) transmission channels plus significant human resources for creating the captioning content, it is also inevitably incomplete in its descriptions of scenes while it will show significant latencies in providing access to live events and news reports. This page will outline an alternative or complementary approach, based on The vOICe technology. Beware though that applicability hinges on the human ability to learn to see with sound..
|
|

|
|
|
|
Single video frame captioned by The vOICe (MP3 audio sample) |
The vOICe technology may complement regular closed captioning and alleviate several of its fundamental weaknesses, by offering a form of closed captioning that is visually complete, as well as extremely concise, while operating in real-time (or very close to that, with typical auditory description latencies of less than one second). The synthesized audio runs automatically synchronized to the visual content from which it is derived on-the-fly. Moreover, it does not require any technical changes to the video source, the studio or the transmission channel, and it functions in situations where no regular closed captions are available, because the non-speech captioning is derived and encoded directly and automatically from the original video content upon arrival.
The digital audio rendering applies to any video input source, by mapping
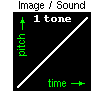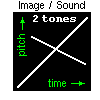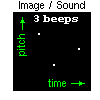 brightness to loudness, elevation to pitch and lateral position to time in
each image scan (using stereo panning for enhanced perception). Thus the
greyscale content of any image or visual scene can be represented in sound.
Moreover, this form of digital captioning is completely independent of language
through its use of non-speech audio, thus adding to the major economic advantages.
brightness to loudness, elevation to pitch and lateral position to time in
each image scan (using stereo panning for enhanced perception). Thus the
greyscale content of any image or visual scene can be represented in sound.
Moreover, this form of digital captioning is completely independent of language
through its use of non-speech audio, thus adding to the major economic advantages.
This approach, as currently implemented by The vOICe for Windows, is extremely general, and provably preserves much of the visual content, at least from a technical perspective, while it also meets several known psychoacoustic constraints that can further limit human hearing. However, there still also exist many open questions about the human ability, and willingness, to learn to perceive, comprehend and make use of this seeing-with-sound technology: the sounds of real-life visual scenes are often extremely complicated. Yet, pending outcomes of further research in that area, the approach is in principle attractive for economic reasons, as well as for the independence offered to blind viewers. Also, some events, such as scene changes, for instance due to jumps in camera position, or the scrolling text at the end of a movie, are easily heard and noticed. No special technical infrastructure is needed other than provisions for the client-side audio rendering of video streams as offered by The vOICe. No longer do blind people need to trust and rely solely on the interpretation of sighted people to tell them what is happening visually through a narrow selection of items of interest. Thereby we guarantee to avoid any form of censorship. With human-made verbal or textual video descriptions, censorship would be inevitable, even with the best of intentions, as a consequence of the required information reduction.
Verbal or textual descriptions of video are in practice always very incomplete, because only by skipping many of the visual items and textures can one attempt to keep up with the rapidly changing scenery in typical television broadcasts.
|
|
Another television-based MP3 sound sample, and links to still other MP3 samples
concerning different visual contexts, can be found on the
Television for the Blind page.
For more general information about closed captioning and video description,
visit the CPB/WGBH
![]() National Center for
Accessible Media (NCAM) website - including information on the DTV Access
Project on closed captioning and video description services for DTV, as well
as on the the Motion Picture Access Project (MoPix) on Rear Window Captioning
(RWC) and DVS Theatrical Systems.
National Center for
Accessible Media (NCAM) website - including information on the DTV Access
Project on closed captioning and video description services for DTV, as well
as on the the Motion Picture Access Project (MoPix) on Rear Window Captioning
(RWC) and DVS Theatrical Systems.

