Central fovea
With the human eye, resolution and sensitivity on the retina are not
spatially uniform. For instance, the central fovea has a markedly higher
resolution than the peripheral parts of the retina. Some might argue
that something similar may be desirable in an auditory representation.
However, one can just as well say that the moving column in our mapping
already forms a kind of auditory (line-shaped) fovea, with the built-in
scanning forming an analogy for (pre-defined) saccades. Furthermore,
our mapping does not enforce a uniform mapping: any pixel we translate
into sound could have come from a spatially distorted image, obtained
via optical means (mirrors, lenses) or obtained via electronics or
software (non-equidistant sub-sampling of a higher resolution image).
In other words, by appropriately distorting the input image to The vOICe,
one could easily create a multi-resolution/multi-grid mapping without
changing the mapping by The vOICe in any way. The same would apply to
non-uniform brightness sensitivity by using an optical filter at the input,
and to non-uniform spectral loudness sensitivity for The vOICe output by
using a frequency dependent electronic filter. Finally, The vOICe already
includes the possibility to handle non-uniform frequency sensitivity by
providing a programmable frequency distribution. All these transformations
will, and should, preserve the topological relations in terms of connectedness
and neighbourhood.
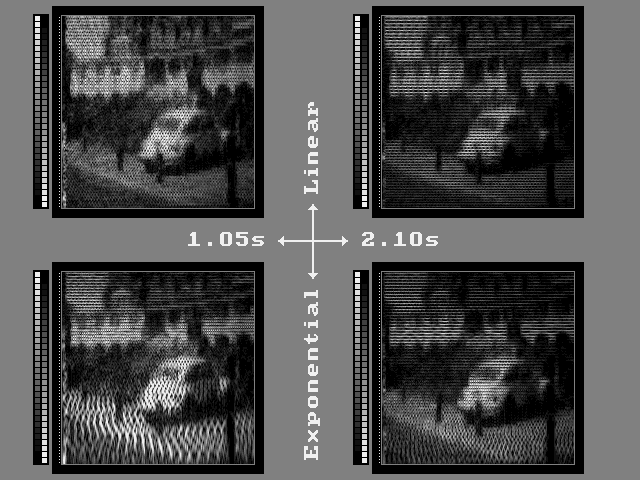
One should keep in mind, though, that the preferred mapping of The vOICe,
using an exponential (hence non-uniform) frequency distribution and a
constant conversion time for each column in a spatially uniform camera
image, has several major advantages: a straight line now ``sounds straight''
whatever the position and orientation of the line in the image is, a
horizontal line gives a constant pitch, etc. The further addition of
spatial distortion to images could easily destroy this desirable
preservation of simplicity and similarity:
consider for instance what would happen to the auditory result for a straight
line running partly through some spatially distorted ``foveal'' region!
Therefore, at this stage it is advised to largely adhere to the mapping of
The vOICe as proposed so far, or at least to stay aware of major detrimental
effects that any significant change to this mapping could have.
Limitations
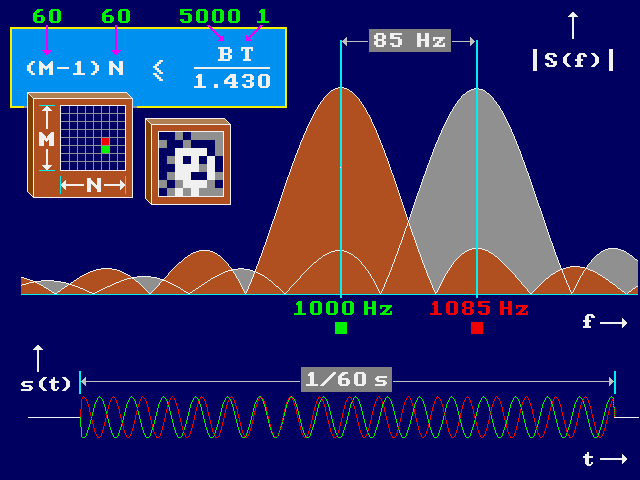
Limitations to the resolution obtainable via the image to sound
mapping result from the
 uncertainty relation
between frequency and time. Mathematically, this limitation is derived from
Fourier analysis. (To make a brief digression: it is in fact an acoustical
analog of the Heisenberg uncertainty relation between energy and time in
quantum mechanics, since energy is, via Planck's constant, proportional to
the frequency of probability waves.) In our application, a detailed mathematical
analysis of side lobe effects leads to an estimated maximum resolution on the
order of 60 × 60 pixels for a one second conversion time and a 5 kHz
auditory bandwidth, using an equidistant frequency distribution. The first side
lobes for time-limited sounds of a given pixel will then worst-case be positioned
at the main lobes of the two neighbouring pixels in a column, while the acoustic
energy in the other-than-first side lobes can be neglected. Thus we limit the
``cross-talk'' or frequency-spreading due to individual pixels. A further
discussion is on the page about the frequency-time uncertainty relation. uncertainty relation
between frequency and time. Mathematically, this limitation is derived from
Fourier analysis. (To make a brief digression: it is in fact an acoustical
analog of the Heisenberg uncertainty relation between energy and time in
quantum mechanics, since energy is, via Planck's constant, proportional to
the frequency of probability waves.) In our application, a detailed mathematical
analysis of side lobe effects leads to an estimated maximum resolution on the
order of 60 × 60 pixels for a one second conversion time and a 5 kHz
auditory bandwidth, using an equidistant frequency distribution. The first side
lobes for time-limited sounds of a given pixel will then worst-case be positioned
at the main lobes of the two neighbouring pixels in a column, while the acoustic
energy in the other-than-first side lobes can be neglected. Thus we limit the
``cross-talk'' or frequency-spreading due to individual pixels. A further
discussion is on the page about the frequency-time uncertainty relation.
Further physiological restrictions to frequency discrimination in
human auditory perception are highly dependent on the particular sound
patterns involved in the experiments. From the width of the so-called
critical bands of the human hearing system one would predict the
separability of at most several tens (20 to 30) of frequency components
for complex sounds in which auditory masking effects dominate.
On the other hand, the difference limen or just noticeable difference (JND),
determined for a single sinusoidal tone with slowly varying frequency,
would suggest the separability of hundreds of components. The use of 64
frequencies in image-to-sound mapping therefore seems reasonable from
a perceptual viewpoint as well. Even if this large number turns out to
be overly optimistic for complicated environmental images, where
informational masking may play an additional significant role, it will
at least reduce the production of annoying auditory artifacts for special
cases like simple images: due to aliasing effects, a lower resolution would
lead to an unwanted staircase-like discontinuous tone sequence for the
single straight line example, while continuous lines should be perceived as
continuous tones.
|
Cochlear implants - looking beyond the horizon
Since the width of the critical bands seems to be largely determined by
the mechanical resonance properties of the cochlea, as indicated by the
much finer frequency resolution for individual sinusoidal tones,
one could theorize about advantages of by-passing the cochlea. This touches
on old debates about the significance of the (mechanical, von Békésy)
place theory of hearing versus the temporal theory of hearing (via neural
temporal analysis). The former likely dominates at higher frequencies
(above, say, ~1 kHz), whereas the latter could dominate at lower frequencies.
Some degree of collective temporal neural processing has been shown to exist
for frequencies up to 5 kHz.
Progress in the development of cochlear implants for the deaf might one
day get beyond the critical band resolution. Having a tonotopic 64-channel
cochlear implant would then exactly match the mapping now provided by
The vOICe. The fact that some 30000 nerve fibers leave the cochlea suggests
that by-passing the mechanical parts of the natural cochlea might remove
the critical band limits - but not the limitations due to the frequency-time
uncertainty relation, while other limitations, like those due to current
spreading, may be introduced. The cochlear implant, in combination with
The vOICe, would then theoretically not only open new vista's for the
deaf and the blind, but even for the deaf-blind.
Neurophysiological issues
From the previous discussion, it is apparent that the most appropriate
cortical map would likely be two-dimensional, involving a tonotopic dimension
to map frequency to place, and a second dimension to map time (delay) to
place. The existence of tonotopic maps is already well established, with
tonotopic connections going all the way from the cochlear ganglion to
the inferior colliculi and the thalamus (medial geniculate body), and
from the thalamus relaying to the auditory cortex in the temporal lobe.
Unfortunately, much less is known about the neurophysiology associated
with the spatio-temporal processing needed for analyzing the dynamics
of time-varying spectra as in speech and music.
Although it is possible to conceive biologically plausible
implementations in which a series of neighbouring one-dimensional tonotopic
maps are connected via - or alternatively receive their inputs from -
continuous (or perhaps even latched?) axonal/synaptic/dendritic neural
delays to form such a two-dimensional cortical sheet, there is presently
little neurophysiological evidence available for that. Nevertheless, one
would expect the existence of such a map to explain the excellent efficiency
with which humans are capable of integrating a sequence of phonemes to
obtain the semantics of a spoken phrase, even in noisy environments
where a number of intermediate phonemes are lost.
In fact, it would seem rather strange if evolution would not
have invented this simple and obvious extension from a single tonotopic
map to a map in which a momentary sound spectrum propagates much like
a moving wave-front to neighbouring (one-dimensional) tonotopic maps in
a cortical sheet. This sheet, which is then a two-dimensional spatial
(spectrographic) map, would act as a short term memory for time-frequency
patterns with time scales on the order of seconds.
Individual spoken words and their immediate context could be recognized,
and subsequently their semantics derived through further interpretation,
by classifying the output of neurons in this sheet via additional
neural structures with afferent connections tapping from this sheet.
One can hypothesize that this is basically what the sensory speech area
of Wernicke is about, as perception of sound direction (which is not even
required for our mapping without stereo extensions) appears to be handled
already in the primary auditory cortex.
In this context, it is interesting to note that the Wernicke area receives
fibers from the visual cortex as well: this plays an important role in the
human ability to understand written text, which again requires accumulation
of information over time. However, for many of these matters a much more
solid foundation is needed to replace or support these conjectures. Given
the large uncertainty even about the neural pathways and processing, it
is much too early to discuss the details of information encoding and the
amount of information preservation in the human brain. Studies of
Kohonen-type computer models of self-organization for spectrographic
analysis could prove helpful in judging the plausibility of spectrographic
map formation during brain development under spectrographically rich
auditory stimuli.
|
![[Frame 1]](kever.gif)


 uncertainty relation
uncertainty relation