Effective visual resolution is clearly of great importance in the development of visual prostheses for the blind. This page discusses why the frequency-time uncertainty relation does not set the theoretical limit to visual resolution attainable with The vOICe. Perceptual relevance remains to be investigated.
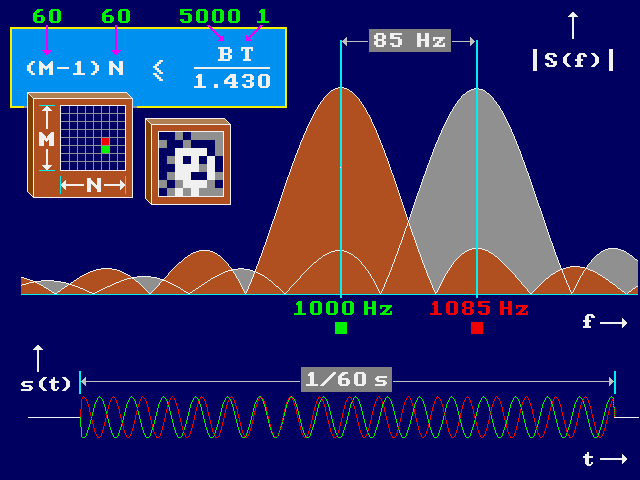
The vOICe synthetic vision technology for the blind is based on mapping images to complex time-varying sounds. In its simplest form, it amounts to a spectrographic synthesis where every pixel is mapped to a brief pure tone of a certain frequency. Ideally, a spectrogram-like mapping would reconstruct the original image. However, a pure tone of less-than-infinite duration does not give a perfect spectral line but a spectral envelope with a main lobe and side lobes. Its spectral envelope will then overlap with the spectral envelope of other simultaneously sounding pure tones of finite duration, a phenomenon called spectral leakage. The shorter the sounds, the greater the spread in frequency, and this trade-off between frequency and time limits the effective resolution in spectrogram-like mappings. The figure below illustrates the overlapping spectral envelopes for two time-limited pure tones, a 1000 Hz tone and a 1085 Hz tone that sound for 1/60 second. The 85 Hz frequency difference between neighbouring tones is what one gets for an equidistant frequency distribution of 60 tones over a 5 kHz bandwidth. These 60 tones and the use of 60 time slices per second amount to a resolution of 60 by 60 pixels if spectral leakage permits, and the overlap among the main spectral lobes in the figure indicates that there is still sufficient separation in the time-frequency plane.
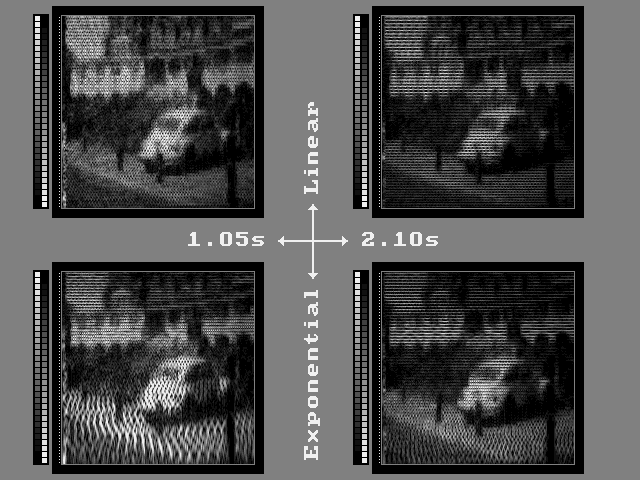
This formed the basis of a publication in 1992 on "An Experimental System for Auditory Image Representations" in the IEEE Transactions on Biomedical Engineering, later reprinted in the 1993 IMIA Yearbook of Medical Informatics. An equidistant frequency distribution is not a good match to the human hearing system, but more appropriate distributions such an exponential frequency scale are subject to the same considerations on spectral leakage, as is illustrated by the spectrographic reconstructions in the figure below.
So there can be an effective localization in both time and frequency under the limitations imposed by the frequency-time uncertainty relation: the product of the uncertainty-in-frequency times the uncertainty-in-time will always be at least one over two pi (i.e., about 0.15915). This same relation lies at the heart of quantum mechanics, where the Heisenberg uncertainty principle applies to energy and time, because energy is, via Planck's constant, proportional to the frequency of probability waves. A related discussion is also given on the web page on wavelets and The vOICe.
However, one can question if the frequency-time uncertainty relation really sets
the fundamental theoretical limit to the attainable image resolution at a given
frame rate for The vOICe auditory display. In fact, one can in a sense beat the
frequency-time uncertainty relation! The frequency-time uncertainty relation does
set a fundamental limit when nothing is known about the source of the waves, but
with The vOICe this source was designed in accordance with a specific
mathematically defined mapping, i.e., a sound generating model. This means that if
one has a time window that contains more sound samples than there are parameters
(pixel brightness values) in the (known) sound generating model, one can in most
cases solve for all those parameters and "beat" the frequency time uncertainty
relation even in very complex sounds. Typical sample rates are often sufficient to
meet this condition. Again, the seeming violation of the frequency-time uncertainty
relation applies only because there is a priori knowledge about the class of
parameterized sounds that is used. Sounds from so-called additive synthesis are a
case in point, where one has a finite and usually fairly small set of amplitude
parameters to solve for the components in a simple superposition of sinusoidal waves.
This concept was applied in a very similar analysis for finite-parameter continuous
time signals, but then applied in a quantum physics context, in the May 2003 article
by Zbyszek Karkuszewski (arXiv:quant-ph/0304206 v2 14 May 2003),
![]() ``Harmonic inversion helps to beat time-energy uncertainty relations.''
The abstract of Karkuszewski's article reads
``Harmonic inversion helps to beat time-energy uncertainty relations.''
The abstract of Karkuszewski's article reads
Abstract - It is impossible to obtain accurate frequencies from time signals of a very short duration. This is a common believe among contemporary physicists. Here I present a practical way of extracting energies to a high precision from very short time signals produced by a quantum system. The product of time span of the signal and the precision of found energies is well bellow the limit imposed by the time-energy uncertainty relation. (Full paper available asThe use of complex or real-valued frequencies does not make any difference to the principle. Now apart from the mathematical principles, the main question for users of The vOICe becomes if it also applies to auditory perception. Can training for certain classes of parameterized (complex) sounds make the human hearing system increasingly "beat" the frequency-time uncertainty relation in the above-described sense? If so, it could prove highly relevant for the design of and training protocols for "super-resolution" auditory displays for the blind. In fact, The vOICe for Android, The vOICe for Windows and The vOICe web app nowadays already synthesize more detail in sound than one reasonably expects resolvable under the uncertainty relation or under standard spectrographic analysis, in part just because it does no harm, but in part also because in principle the listener could learn to exploit (even implicitly acquired) a priori knowledge about the sound generating model, and it would be extremely interesting and important if (blind) humans could indeed adapt and learn to exploit the underlying sound structure of what is still left after passing the cochlea and early stages of neural processing. Vice versa, one would then like to know how one can train the human brain to achieve best visual acuity through an auditory display like The vOICe.PDF file.)
Placing a bet on long-term use of The vOICe, one can argue that it is best to use a fixed phase evolution per tone in order to make phases as detectable and predictable as possible from entire soundscapes. The fixed phase evolution may then over time get ingrained in the brain to support best possible reconstruction of the brightness of individual pixels at any time point in a soundscape without having to separately decipher local phase from a specific soundscape: phases as a function of time are exactly the same for all soundscapes and thus known and learnable in advance. On the one hand one might feel tempted to make soundscapes sound more pleasant by adjusting local phases of subsequent tones in for instance slanted lines, such that the sound of a slanted line would approximate that of a continuously rising or falling frequency, but on the other hand that would make the phase evolution dependent on image content that varies per soundscape, thus defeating the possibility of learning to exploit an ingrained fixed phase pattern for higher resolution vision. We now bet on the brain to learn to no longer perceive the "roughness" in soundscapes that arises from a fixed phase evolution per tone, in order to maximize the possibilities for the brain to extract higher resolution visual detail than the frequency-time uncertainty relation would normally allow for. Moving to a skill level where this matters might take many years of use, or it may never happen.
The frequency-time template has been harmonized for mutually consistent platform-independent results as of The vOICe for Windows 1.94+, The vOICe for Android 2.31+ and The vOICe web app 1.24+. If the fixed phase pattern for one implementation gets ingrained in the brain it will thus readily carry over to using it with one of the other implementations without having to relearn and ingrain another phase pattern.
Other related or relevant literature:
![]() DOI). Available Available
DOI). Available Available
![]() online (PDF file).
online (PDF file).![]() DOI). Available
DOI). Available
![]() online (PDF file).
online (PDF file).