Appendix B
Input Format for Training Data
In the following sections, a preliminary
specification is given of the input file format used for neural modelling. Throughout the input
file, delimiters will be used to separate numerical items, and comments may be freely used for
the sake of readability and for documentation purposes:
DELIMITERS
At least one space or newline must separate subsequent data items (numbers).
COMMENTS
Comments are allowed at any position adjacent to a delimiter. Comments within numbers are
not allowed. The character pair ”/*” (without the quotes) starts a comment, while ”*/” ends it.
Comments may not be nested, and do not themselves act as delimiters. This is similar, but not
identical, to the use in the Pstar input language and the C programming language. Furthermore,
the ”/* ... */” construction may be omitted if the comment does not contain delimited
numbers.
Example:
Any non-numeric comment, or also a
non-delimited number, as in V2001
/* Any number of comment lines, which
* may contain numbers, such as 1.234
*/
B.1 File Header
The input file begins—neglecting any comments—with the integer number of neural networks that
will be simultaneously trained. Subsequently, for each of these neural networks the preferred
topology is specified. This is done by giving, for each network, the total integer number of
layers
K + 1, followed by a list of integer numbers N0 ... NK for the width of each layer. The number
of network inputs N0 must be equal for all networks, and the same holds for the number of
network outputs NK.
Example:
2 /* 2 neural networks: */
3 3 2 3 /* 1st network has 3 layers in a 3-2-3 topology */
4 3 4 4 3 /* 2nd network has 4 layers in a 3-4-4-3 topology */
These neural network specifications are followed by data about the device or subcircuit that is to
be modelled. First the number of controlling (independent) input variables of a device or
subcircuit is specified, given by an integer which should—for consistency—equal the number of
inputs N0 of the neural networks. It is followed by the integer number of (independent) output
variables, which should equal the NK of the neural networks.
Example:
# input variables # output variables
3 3
After stating the number of input variables and output variables, a collection of data blocks
is specified, in an arbitrary order. Each data block can contain either dc data and
(optionally) transient data, or ac data. The format of these data blocks is specified in the
sections B.2 and B.3. However, the use of neural networks for modelling electrical
behaviour leads to additional aspects concerning the interpretation of inputs and
outputs in terms of electrical variables and parameters, which is the subject of the next
section.
B.1.1 Optional Pstar Model Generation
Very often, the input variables will represent a set of independent terminal voltages, like the v
discussed in the context of Eq. (3.19), and the output variables will be a set of corresponding
independent (target) terminal currents 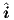 . In the optional automatic generation of models for
analogue circuit simulators, it is assumed that we are dealing with such voltage-controlled
models for the terminal currents. In that case, we can interpret the above 3-input,
3-output examples as referring to the modelling of a 4-terminal device or subcircuit
with 3 independent terminal voltages and 3 independent terminal currents. See also
section 2.1.2. Proceeding with this interpretation in terms of electrical variables, we will now
describe how a neural network having more inputs than outputs will be translated
during the automatic generation of Pstar behavioural models. It is not allowed to have
fewer inputs than outputs if Pstar models are requested from the neural modelling
software.
. In the optional automatic generation of models for
analogue circuit simulators, it is assumed that we are dealing with such voltage-controlled
models for the terminal currents. In that case, we can interpret the above 3-input,
3-output examples as referring to the modelling of a 4-terminal device or subcircuit
with 3 independent terminal voltages and 3 independent terminal currents. See also
section 2.1.2. Proceeding with this interpretation in terms of electrical variables, we will now
describe how a neural network having more inputs than outputs will be translated
during the automatic generation of Pstar behavioural models. It is not allowed to have
fewer inputs than outputs if Pstar models are requested from the neural modelling
software.
If the number of inputs N0 is larger than or equal to the number of outputs NK, then the first
NK (!) inputs will be used to represent the voltage variables in v. In a Pstar-like notation,
we may write the elements of this voltage vector as a list of voltages V(T0,REF) ...
V(T< NK - 1 >,REF). Just as in Fig. 2.1 in section 2.1.2, the REF denotes any
reference terminal preferred by the user, so V(T<i>,REF) is the voltage between
terminal (node) T<i> and terminal REF. The device or subcircuit actually has NK + 1
terminals, because of the (dependent) reference terminal, which always has a current
that is the negative sum of the other terminal currents, due to charge and current
conservation. The NK outputs of the neural networks will be used to represent the current
variables in 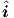 , of which the elements can be written in a Pstar-like notation as terminal
current variables I(T0) ... I(T< NK - 1 >). However, any remaining N0 - NK inputs
are supposed to be time-independent parameters PAR0 ... PAR< N0 - NK - 1 >,
which will be included as such in the argument lists of automatically generated Pstar
models.
, of which the elements can be written in a Pstar-like notation as terminal
current variables I(T0) ... I(T< NK - 1 >). However, any remaining N0 - NK inputs
are supposed to be time-independent parameters PAR0 ... PAR< N0 - NK - 1 >,
which will be included as such in the argument lists of automatically generated Pstar
models.
To clarify this with an example: N0 = 5 and NK = 3 would lead to automatically generated
Pstar models having the form
MODEL: NeuralNet(T0,T1,T2,REF) PAR0, PAR1;
...
END;
with 3 independent input voltages V(T0,REF), V(T1,REF), V(T2,REF), 3 independent
terminal currents I(T0), I(T1), I(T2), and 2 model parameters PAR0 and PAR1.
B.2 DC and Transient Data Block
The dc data block is represented as a special case of a transient data block, by giving only a
single time point 0.0 (which may also be interpreted as a data block type indicator),
corresponding to ts,is=1 = 0 in Eq. (3.18), followed by input values that are the elements of
xs,is(0), and by target output values that are the elements of 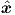 s,is.
s,is.
In modelling electrical behaviour in the way that was discussed in section B.1.1, the xs,is(0) of
Eq. (3.18) will become the voltage vector v of Eq. (3.19), of which the elements will be the
terminal voltages V(T0,REF) ... V(T< NK - 1 >,REF), while the xs,is of Eq. (3.18) will
become the current vector 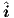 s,is of Eq. (3.19), of which the elements will be the terminal currents
I(T0) ... I(T< NK - 1 >).
s,is of Eq. (3.19), of which the elements will be the terminal currents
I(T0) ... I(T< NK - 1 >).
Example:
0.0 /* single time point */
3.0 4.0 5.0 /* bias voltages */
5.0e-4 -5.0e-4 0.0 /* terminal currents */
However, it should be emphasized that an interpretation in terms of physical quantities like
voltages and currents is only required for the optional automatic generation of behavioural
models for analogue circuit simulators. It does not play any role in the training of the underlying
neural networks.
Extending the dc case, a transient data block is represented by giving multiple time points ts,is,
always starting with the value 0.0, and in increasing time order. Time points need not be
equidistant. Each time point is followed by the elements of the corresponding xs,is(0) and
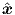 s,is.
s,is.
In the electrical interpretation, this amounts to the specification of voltages and currents as a
function of time.
Example:
time voltages currents
0.0 3.0 4.0 5.0 5.0e-4 -5.0e-4 0.0
1.0e-9 3.5 4.0 5.0 4.0e-4 -4.1e-4 0.0
2.5e-9 4.0 4.0 5.0 3.0e-4 -3.3e-4 0.0
... ... ...
B.3 AC Data Block
The small-signal ac data block is distinguished from a dc or transient data block by starting
with a data block type indicator value -1.0. This number is followed by the dc bias represented
by the elements of xb(0) as in Eq. (3.59).
In the electrical interpretation, the elements of xb(0) are the dc bias voltages V(T0,REF) ...
V(T< NK - 1 >,REF).
After specifying the dc bias, the frequency values fb,ib are given, each of them followed by the real
and imaginary values of all the elements of an NK ×NK target transfer matrix  b,ib. The required
order of matrix elements is the normal reading order, i.e., from left to right, one row after the
other.
b,ib. The required
order of matrix elements is the normal reading order, i.e., from left to right, one row after the
other.
In the electrical interpretation, the transfer matrix contains the real and imaginary parts of
Y-parameters.
 b,ib is then equivalent to the so-called admittance matrix Y of the device or subcircuit that
one wants to model. The frequency fb,ib and the admittance matrix Y have the same meaning
and element ordering as in the Pstar specification of a multiport YNPORT, under the
assumption that a common reference terminal REF had been selected for the set of ports
[13, 14]:
b,ib is then equivalent to the so-called admittance matrix Y of the device or subcircuit that
one wants to model. The frequency fb,ib and the admittance matrix Y have the same meaning
and element ordering as in the Pstar specification of a multiport YNPORT, under the
assumption that a common reference terminal REF had been selected for the set of ports
[13, 14]:
f1 y11r y11i y12r y12i ... ymmr ymmi
f2 y11r y11i y12r y12i ... ymmr ymmi
...
fn y11r y11i y12r y12i ... ymmr ymmi
where the r denotes a real value, and the i an imaginary value. The admittance matrix Y has
size NK ×NK; NK is here denoted by m. The ykl≡y<k><l> = (Y )kl can be interpreted as the
complex-valued ac current into terminal T<k> of a linear(ized) device of subcircuit, resulting
from an ac voltage source of amplitude 1 and phase 0 between terminal T<l> and terminal
REF.
Frequency values may be arbitrarily selected. A zero frequency is also allowed (which can be
used for modelling dc conductances). The matrix element order corresponds to the normal
reading order, i.e., from left to right, one row after the other:
read in the order:
/ (y11r,y11i) ... (y1mr,y1mi) \ 1 2 ... m
H = Y = | (y21r,y21i) ... (y2mr,y2mi) | m+1 m+2 ... 2m
| ... ... | ... ... ...
\ (ym1r,ym1i) ... (ymmr,ymmi) / (m-1)m+1 (m-1)m+2 ... m*m
Contrary to Pstar, the application is here not restricted to linear multiports, but includes
nonlinear multiports, which is why the dc bias had to be specified as well.
Example:
type dc bias voltages
-1.0 3.0 4.0 5.0
frequency yk1r yk1i yk2r yk2i yk3r yk3i
1.0e9 1.3e-3 1.1e-3 0.3e-3 0.8e-3 0.3e-3 3.1e-3 /* k=1 */
1.3e-3 1.1e-3 0.3e-3 0.8e-3 0.3e-3 3.1e-3 /* k=2 */
1.3e-3 1.1e-3 0.3e-3 0.8e-3 0.3e-3 3.1e-3 /* k=3 */
2.3e9 2.1e-3 1.0e-3 0.7e-3 1.5e-3 0.2e-3 2.0e-3 /* k=1 */
1.0e-3 0.1e-3 0.8e-3 0.2e-3 0.6e-3 3.1e-3 /* k=2 */
1.1e-3 0.1e-3 0.5e-3 0.7e-3 0.9e-3 1.1e-3 /* k=3 */
... ... ... ...
Optional alternative ac data block specifications:
Alternatively, ac data blocks may also be given by starting with a data block type indicator
value -2.0 instead of -1.0. The only difference is that pairs of numbers for the complex-valued
elements in Y are interpreted as (amplitude, phase) instead of (real part, imaginary part). The
amplitude given must be the absolute (positive) amplitude (not a value in decibel). The phase
must be given in degrees. If a data block type indicator value -3.0 is used, the (amplitude,
phase) form with absolute amplitude is assumed during input processing, with the phase
expressed in radians.
B.4 Example of Combination of Data Blocks
Taking the above example parts together, one obtains, for an arbitrary order of data
blocks:
neural network definitions
2
3 3 2 3
4 3 4 4 3
inputs and outputs
3 3
ac block
-1.0 3.0 4.0 5.0
1.0e9 1.3e-3 1.1e-3 0.3e-3 0.8e-3 0.3e-3 3.1e-3
1.3e-3 1.1e-3 0.3e-3 0.8e-3 0.3e-3 3.1e-3
1.3e-3 1.1e-3 0.3e-3 0.8e-3 0.3e-3 3.1e-3
2.3e9 2.1e-3 1.0e-3 0.7e-3 1.5e-3 0.2e-3 2.0e-3
1.0e-3 0.1e-3 0.8e-3 0.2e-3 0.6e-3 3.1e-3
1.1e-3 0.1e-3 0.5e-3 0.7e-3 0.9e-3 1.1e-3
transient block
0.0 3.0 4.0 5.0 5.0e-4 -5.0e-4 0.0
1.0e-9 3.5 4.0 5.0 4.0e-4 -4.1e-4 0.0
2.5e-9 4.0 4.0 5.0 3.0e-4 -3.3e-4 0.0
dc block
0.0 3.0 4.0 5.0 5.0e-4 -5.0e-4 0.0
The present experimental software implementation can read an input file containing the text of
this example.
Only numbers are required in the input file, since any other (textual) information is
automatically discarded as comment. In spite of the fact that no keywords are used, it is still
easy to locate any errors due to an accidental misalignment of data as a consequence of some
missing or superfluous numbers. For this purpose, a -trace software option has been
implemented, which shows what the neural modelling program thinks that each number
represents.